.In the
Using ElasticSearch as external data store with apache hive entry i talked about how you can create a table in Hive so that actual data is stored in ElasticSearch. Problem with that approach was that i had to pass the full path to
elasticsearch-hadoop-hive-<eshadoopversion>.jar as parameter every time.
hive -hiveconf hive.aux.jars.path=/opt/elastic/elasticsearch-hadoop-2.4.3/dist/elasticsearch-hadoop-hive-2.4.3.jar;
Other option for doing same thing is to open hive session and then calling following command as first thing
ADD JAR /opt/elastic/elasticsearch-hadoop-2.4.3/dist/elasticsearch-hadoop-hive-2.4.3.jar;
Problem with both these approaches is that you will have to keep letting hive know the full path to elasticsearch jars every single time. Instead you can take care of this issue by copying
elasticsearch-hadoop-hive-<eshadoopversion>.jar into same directory on every node in your local machine. In my case i copied it to
/usr/lib/hive/lib directory by executing following command
sudo cp /opt/elastic/elasticsearch-hadoop-2.4.3/dist/elasticsearch-hadoop-hive-2.4.3.jar /usr/lib/hive/lib/.
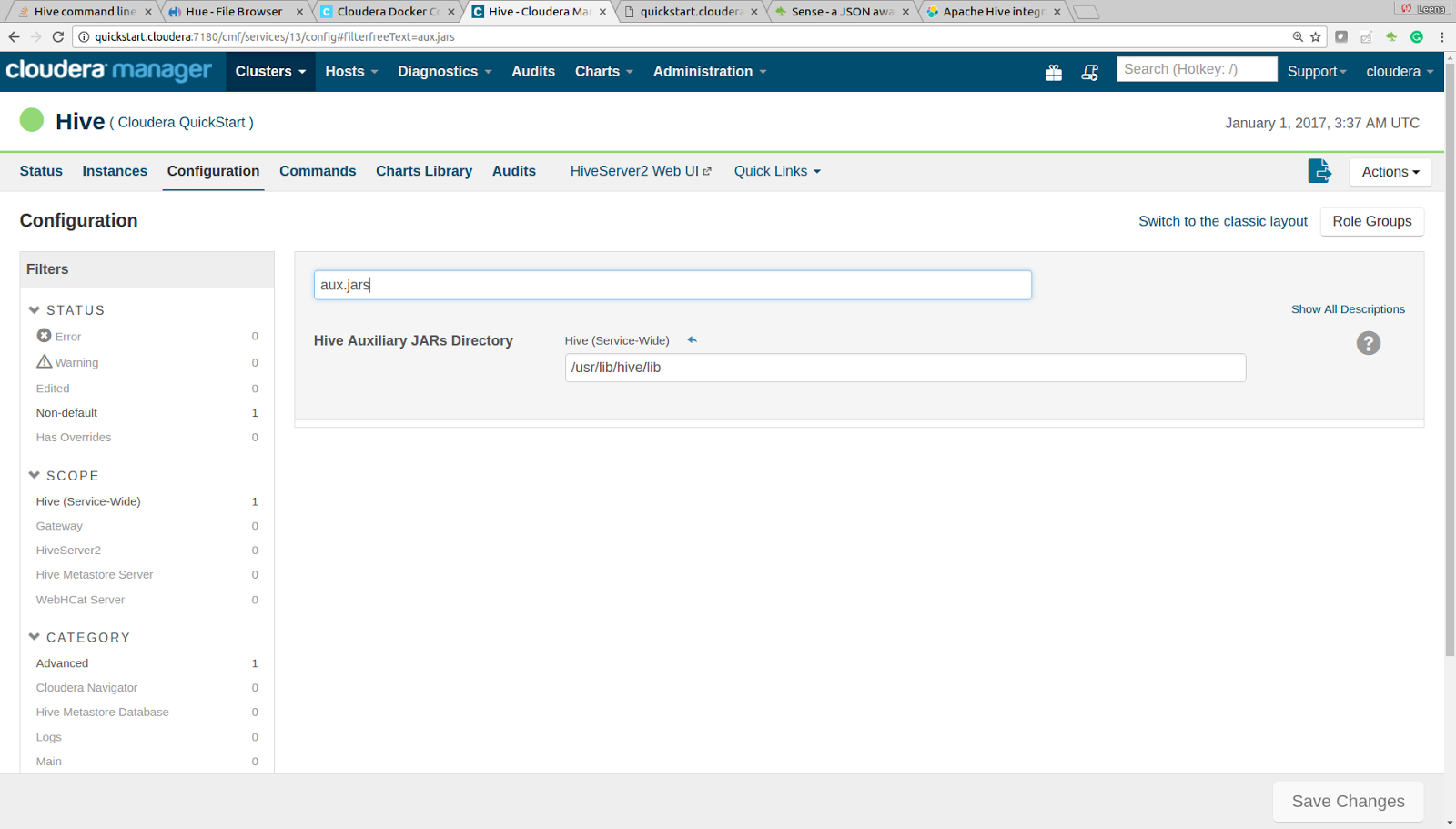
Then set the value of Hive Auxiliary JARs Directory
hive.aux.jars.path property to
/usr/lib/hive/lib directory like this.
Then restart the hive service and now you should be able to access any elastic search backed table without adding the elasticsearch hadoop jar explicitly
Nice Article thanks for Sharing custom web development
ReplyDeleteThanks for sharing useful information. Keep on sharing.
ReplyDeleteWeb design canada
Digital marketing canada
Great post. It was very helpful.
ReplyDeleteCreative learners can improve practical design knowledge through this learn ui ux program designed with real-time UI and UX concepts.
ReplyDelete