-
First i looked at my hadoop-site.xml to find out value of
dfs.data.direlement, which points to where the data is stored. In my case its/home/user/datadirectory<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.data.dir</name> <value>/home/user/data</value> </property> </configuration> -
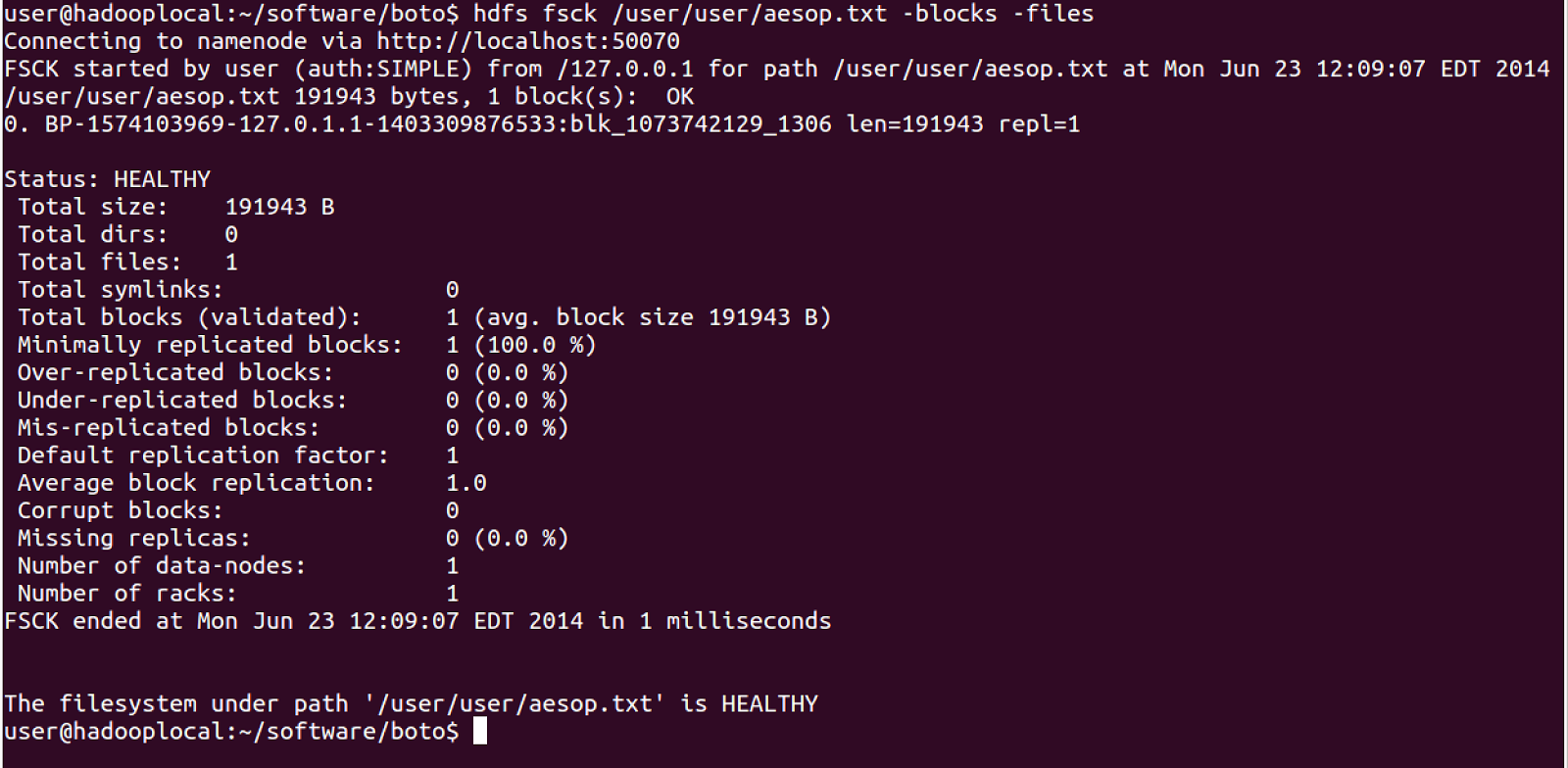
There is a file /user/user/aesop.txt stored in my HDFS and i wanted to see where the file is stored so i did execute
hdfs fsck /user/user/aesop.txt -blocks -filescommand to get list of blocks where this file is locatedIt is stored in
BP-1574103969-127.0.1.1-1403309876533:blk_1073742129_1306 -
When i looked under
/home/user/data/current directory i sawBP-1574103969-127.0.1.1-1403309876533which gives me first part of the block name, and it has bunch of subdirectories
-
The next part was to find
blk_1073742129_1306which is second part of the block name so i did search for it without _1306 the last part and i found .meta file and a normal file that contains the actual content of aesop.txt, when i opened it i could see the content of the file like this
Finding out the blocks used for storing file in HDFS
The HDFS stores files by breaking them into blocks of 64 MB in size (default block size but you can change it). It stores these blocks across one or more disks/machines, Unlike filesystem for a single disk, a file in HDFS that is smaller than single block does not occupy a fully block's worth of underlying storage.
Map tasks in Map Reduce operate on one block at a time (InputSplit takes care of assigning different map task to each of teh block).
Replication is handled at block level, what it means is HDFS will replicate the block to different machine and if one of the block is corrupted or one of the machine where the block is stored is down it can read that from different machine, in case of corrupted unreachable block HDFS will take care of replication of the block to bring the replication factor back to the normal level.
Some applications may choose to set a high replication factor for blocks in popular file to spread the read load on the cluster
I wanted to figure out how the file gets stored in HDFS(/user/user/aesop.txt file as example), so i tried these steps on my local hadoop single-node cluster.


Making HTTPS outbound calls from mule
In the Getting markup from HTTPS connection in Java program entry i talked about how to make HTTPS call from stand alone java application. Recently i had to figure out how to make HTTPS call from Mule as part of flow, and these are the steps that i followed
- First step is to download the certificate for the site, but the InstallCert.java is no available on Oracle blog, instead i had to download it from here
- The next step is to compile the InstallCert.java by executing
javac InstallCert.java - One issue in using the trust store with Mule is that the password for the trust store file should be not null. So i had to execute the InstallCert command with changeit as password (same as oracle java's default password) like this
java InstallCert wpcertification.blogspot.com changeit - After executing last step you should see
jssecacertsfile in your local directory, that is your trust store file -
Next step is to create a HTTP connector in mule and while configuring go to security tab, check Enable HTTPS and configure the trust store to point to the
jssecacertsfile created in the last step and usechangeitas password
-
Last step is to add HTTP call in your flow, while adding that call use the HTTP connector that you configured in the previous step

- Now you can go ahead and test the flow and you should be able to make HTTPS call


WordCount MapReduce program using Pydoop (MapReduce framework for Python)
In WordCount MapReduce program using Hadoop streaming and python entry i used Hadoop Streaming for creating MapReduce program, but that program is quite verbose and it has limitations such as you cannot use counters,.. etc.
So i decided to develop same program using Pydoop, which is framework that makes is easy to developing Hadoop Map Reduce program as well as working with HDFS easier. I followed these steps
- First i followed instructions on pydoop installation page to install pydoop on my machine. I ran into some issues during that process but eventually had pydoop installed
-
Next i did create a HelloPydoop.py file which contains mapper function and reducer function like this. The mapper function gets linenumber and line at a time, in that function i am taking care of breaking the line into words and then writing them into output (
writer.emit()). In the reducer method i am getting word and incount in the(key, [value,value1]format. Which is different that Hadoop streaming where i have to take care of change in key, so this code is much compact -
Once my HelloPydoop.py file is ready i could invoke it by passing to pydoop script in this aesop.txt is the name of the input file in HDFS and i want the output to get generated in output/pydoop directory in HDFS.
pydoop script /home/user/PycharmProjects/HelloWorld/Pydoop/HelloPydoop.py aesop.txt output/pydoop -
After the map reducer is done executing i can look at its output by executing
hdfs dfs -cat output/pydoop/part-00000command
WordCount MapReduce program using Hadoop streaming and python
I wanted to learn how to use Hadoop Streaming, which allows us to use scripting language such as Python, Ruby,.. etc for developing Map Reduce program. The idea is instead of writing Java classes for Mapper and Reducer you develop 2 script files (something that can be executed from command line) one for mapper and other for reducer and pass it to Hadoop. Hadoop will communicate to the script files using standard input/output, which means for both mapper and reducer hadoop will pass input on standard input and your script file will read it from standard input. Once your script is done processing the data in either mapper or reducer it will write output to standard output that will get sent back to hadoop.
I decided to create Word Count program that takes a file as input and counts occurrence of every word in the file and writes it in output. I followed these steps
-
I started by creating a mapper.py file like this, In the mapper i am reading one line from input at a time and then splitting it into pieces and writing it to output in
(word,1)format. In the mapper whatever i write in output gets passed back to Hadoop, so i could not use standard output for writing debug statements. So i configured file logger that generates debug.log in the current directory -
Next i created a reducer.py program that reads one line at a time and splits it on tab character. In the split first part is word and second is the count. Now one difference between java reducer and streaming reducer is in Java your reduce method gets input like this
(key, [value1, value2,value3]),(key1, [value1, value2,value3]). In streaming it gets called with one key and value every time like this(key,value1),(key,value2),(key,value3),(key1,value),(key1,value2),(key1,value3), so you will have to remember what key your processing and handle the change in key. In my reducer i am keeping track of current key, and for every value of the current key i keep accumulating it, when the key changes i use that opportunity to dump the old key and count -
One good part with developing using scripting is that you can test your code without hadoop as well. In this case once my mapper and reducer are ready i can test it on command line using
data | mapper | sort | reducerformat. In my case the mapper and reducer files are in /home/user/workspace/HadoopPython/streaming/ directory. and i have a sample file in home directory so i could test my program by executing it like thiscat ~/sample.txt | /home/user/workspace/HadoopPython/streaming/mapper.py | sort | /home/user/workspace/HadoopPython/streaming/reducer.py -
After working through bugs i copied aesop.txt in in root of my HDFS and then i could use following command to execute my map reduce program.
hadoop jar /usr/local/hadoop/share/hadoop/tools/lib/hadoop-streaming-2.4.0.jar -input aesop.txt -output output/wordcount -mapper /home/user/workspace/HadoopPython/streaming/mapper.py -reducer /home/user/workspace/HadoopPython/streaming/reducer.py -
Once the program is done executing i could see the output generated by it using following command
hdfs dfs -cat output/wordcount/part-00000
WordCount program writtten using Spark framework written in python language
In the WordCount(HelloWorld) MapReduce program entry i talked about how to build a simple WordCount program using MapReduce. I wanted to try developing same program using Apache Spark but using Python, so i followed these steps
- Download version of spark that is appropriate for your hadoop from Spark Download page. In my case i am using Cloudera CHD4 VM image for development so i did download CDH4 version
- I did extract the spark-1.0.0-bin-cdh4.tgz in /home/cloudera/software folder
-
Next step is to build a WordCount.py program like this. This program has 3 methods in this
- flatMap: This method takes a line as input and splits it on space and publishes those words
- map: This method takes a word as input and publishesh a tuple in
word, 1format - reduce: This method takes care of adding all the counters together
counts = distFile.flatMap(flatMap).map(map).reduceByKey(reduce)takes care of tying everything together -
Once WordCount.py is ready you can execute it like this by providing it path of the WordCount.py and input and output path
./bin/spark-submit --master local[4] /home/cloudera/workspace/spark/HelloSpark/WordCount.py file:///home/cloudera/sorttext.txt file:///home/cloudera/output/wordcount -
Once the program is done executing you can take a look at the output by executing following command
more /home/cloudera/output/wordcount/part-00000
Importing data from RDBMS into Hive using create-hive-table of sqoop
In the Importing data from RDBMS into Hive i blogged about how to import data from RDBMS into Hive using Sqoop. In that case the import command took care of both creating table in Hive based on RDMBS table as well as importing data from RDBMS into Hive.
But Sqoop can also be used to import data stored in HDFS text file into Hive. I wanted to try that out, so what i did is i created the contact table in Hive manually and then used the contact table that i exported as text file into HDFS as input
-
First i used sqoop import command to import content of Contact table into HDFS as text file. By default sqoop will use , for separating columns and newline for separating
After import is done i can see content of the text file by executingsqoop import --connect jdbc:mysql://macos/test --table contact -m 1hdfs dfs -cat contact/part-m-00000like this
-
After that you can use sqoop to create table into hive based on schema of the CONTACT table in RDBMS. by executing following command
sqoop create-hive-table --connect jdbc:mysql://macos/test --table Address --fields-terminated-by ',' -
Last step is to use Hive for loading content of contact text file into contact table. by executing following command.
LOAD DATA INPATH 'contact' into table contact;

Importing data from RDBMS into Hive using sqoop
In the Importing data from RDBMS into Hadoop i blogged about how to import content of RDBMS into Hadoop Text file using Sqoop. But its more common to import the content of RDMBS into Hive. I wanted to try that out, so i decided to import content of the Contact table that i created in the Importing data from RDBMS into Hadoop entry in Contact table in Hive on my local machine. I followed these steps
- First take a look at content of Contact table in my local MySQL like this (
SELECT * from CONTACT)
- Next step is to use sqoop import command like this
As you will notice this command is same as hive import command that i used in last blog entry to import content of RDMBS into text file, only difference is i had to addsqoop import --connect jdbc:mysql://macos/test --table Address -m 1 --hive-import--hive-importswitch -
This command takes care of first creating Contact table into Hive and then importing content of CONTACT table from RDMBS into CONTACT table in Hive. Now i can see content of Contact table in Hive like this



Importing data from RDBMS into Hadoop using sqoop
Apache Sqoop lets you import content of RDBMS into Hadoop. By default it will import content of a table into hadoop text file with columns separated by , and rows separated by new line. I wanted to try this feature out so i decided to import table from MySQL database on my local machine into HDFS using Sqoop
- First i created a CONTACT table in my local like this
CREATE TABLE `CONTACT` ( `contactid` int(11) NOT NULL, `FNAME` varchar(45) DEFAULT NULL, `LNAME` varchar(45) DEFAULT NULL, `EMAIL` varchar(45) DEFAULT NULL, PRIMARY KEY (`contactid`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; -
Then i had to add few records into CONTACT table by using this syntax
INSERT INTO `test`.`CONTACT`(`contactid`,`FNAME`,`LNAME`,`EMAIL`)VALUES(1,'Sunil','Patil','sdpatil@gmail.com'); - Then on the command line i had to execute following command to run Sqoop so that it imports content of
This command tells sqoop to connect to test database in mysql on localhostsqoop import --connect jdbc:mysql://localhost/test --table Contactjdbc:mysql://localhost/testand import content of CONTACT table. - After executing the command when i looked into the HDFS i could see that there is Contact directory (same as table name, if you want to use different directory name then table name pass --target-dir argument ), that directory contains 4 files.

-
Now if i look inside one of the part-m files i could see it has content of CONTACT table dumped inside it like this

- By default sqoop opens multiple threads to import content of the table. If you want you can control number of map jobs it runs. In my case the CONTACT table has only 12 rows so i want sqoop to run only 1 map job, so i used following command
sqoop import --connect jdbc:mysql://localhost/test --table Contact --target-dir contact1 -m 1


Subscribe to:
Comments (Atom)