The WebSphere Application Server Transaction Manager writes to its transaction recovery logs when it handles global transactions that involve two or more resources. Transaction recovery logs are stored on disk and are used for recovering in-flight transactions from system crashes or process failures. To enable WebSphere application server transaction peer recovery, it is necessary to place the recovery logs on a highly available file system, such as IBM SAN FS or NAS, for all the application servers within the same cluster to access. All application servers must be able to read from and write to the logs.
For a peer server to recover in-flight transactions, any database locks associated with the failed transactions should be released prior to the recovery. You need to use the lease-based exclusive locking protocol, such as Common Internet File System (CIFS) or Network File System (NFS) Version4, to access remote recovery logs from WebSphere application server nodes. Without the lease-based locking support, if one of the nodes crashes, locks held by all the processes on that node will not automatically be released. As a result, the transactions cannot be completed, and database access can be impaired due to the unreleased locks
In the event of a server failure, the transaction service of the failed application server is out of service. Also, the in-flight transactions that have not be committed might leave locks in the database, which blocks the peer server from gaining access to the locked records. There are only two ways to complete the transactions and release the locks. One is to restart the failed server and the other is to start an application server process on another box that has access to the transaction logs. Using the new HAManager support, a highly available file system and a lease-based locking protocol, a recovery process will be started in a peer member of the cluster. The recovery locks are released and in-flight transactions are committed.
Showing posts with label wlmandfailover. Show all posts
Showing posts with label wlmandfailover. Show all posts
What is a core group
A core group is a high availability domain within a cell. It serves as a physical grouping of JVMs in a cell that are candidates to host singleton services. It can contain stand-alone servers, cluster members, Node Agents, or the Deployment Manager.
A cell must have at least one core group. The WebSphere Application Server creates a default core group, called DefaultCoreGroup, for each cell. Each JVM process can only be a member of one core group. Naturally, cluster members must belong to the same core group. At runtime, the core group and policy configurations are matched together to form high availability groups


A set of JVMs can work together as a group to host a highly available service. All JVMs with the potential to host the service join the group when they start. If the scope of the singleton (such as a Transaction Manager or a messaging engine) is a WebSphere cluster then all members of the cluster are part of such a group of JVMs that can host the service.
In a large-scale implementation with clusters spanning multiple geographies, you
can create multiple core groups in the cell and link them together with the core
group bridge to form flexible topologies. The most important thing is that every
JVM in a core group must be able to open a connection to all other members of
the core group.
A core group cannot extend beyond a cell, or overlap with other core groups. Core groups in the same cell or from different cells, however, can share workload management routing information using the core group bridge service
A cell must have at least one core group. The WebSphere Application Server creates a default core group, called DefaultCoreGroup, for each cell. Each JVM process can only be a member of one core group. Naturally, cluster members must belong to the same core group. At runtime, the core group and policy configurations are matched together to form high availability groups


A set of JVMs can work together as a group to host a highly available service. All JVMs with the potential to host the service join the group when they start. If the scope of the singleton (such as a Transaction Manager or a messaging engine) is a WebSphere cluster then all members of the cluster are part of such a group of JVMs that can host the service.
In a large-scale implementation with clusters spanning multiple geographies, you
can create multiple core groups in the cell and link them together with the core
group bridge to form flexible topologies. The most important thing is that every
JVM in a core group must be able to open a connection to all other members of
the core group.
A core group cannot extend beyond a cell, or overlap with other core groups. Core groups in the same cell or from different cells, however, can share workload management routing information using the core group bridge service
What is hamanager
IBM WebSphere Application Server Network Deployment V6 introduces a new feature called High Availability Manager (commonly called HAManager) that enhances the availability of WebSphere singleton services such as transaction or messaging services. It provides a peer recovery mechanism for in-flight transactions or messages among clustered WebSphere application servers.HAManager enhances teh availability of singleton services in WebSphere. THese singleton services include
The HAManager runs as a service within each WebSphere process (Deployment Manager, Node Agents, or application servers) that monitors the health of WebSphere singleton services. In the event of a server failure, the HAManager will failover any singleton service that was running on the failed server to a peer server. Examples of such a failover include the recovery of any in-flight transactions or restarting any messaging engines that were running on the failed server.The HAManager runs as a service within each WebSphere process (Deployment Manager, Node Agents, or application servers) that monitors the health of WebSphere singleton services. In the event of a server failure, the HAManager will failover any singleton service that was running on the failed server to a peer server. Examples of such a failover include the recovery of any in-flight transactions or restarting any messaging engines that were running on the failed server.
- Transaction service - Transaction log recovery
- Messaging service - Messaging engine restarting
The HAManager runs as a service within each WebSphere process (Deployment Manager, Node Agents, or application servers) that monitors the health of WebSphere singleton services. In the event of a server failure, the HAManager will failover any singleton service that was running on the failed server to a peer server. Examples of such a failover include the recovery of any in-flight transactions or restarting any messaging engines that were running on the failed server.The HAManager runs as a service within each WebSphere process (Deployment Manager, Node Agents, or application servers) that monitors the health of WebSphere singleton services. In the event of a server failure, the HAManager will failover any singleton service that was running on the failed server to a peer server. Examples of such a failover include the recovery of any in-flight transactions or restarting any messaging engines that were running on the failed server.
EJB Container failover and WLM
The EJB client ORB plays same role in EJB world as that of HTTP Server plugin plays in the Web application world. Irrepective of if the client is a standalone Java client, another EJB or a servlet in a web application server in which the EJB is running, the EJB client ORB eliminates any one point of failure by dispatching requests among 1 to n application servers residing on multiple nodes. The EJB Client ORB will redirect EJB requests across cluster once a server is unavailable or not responding to response.
Work load management and clustering
Clustering application servers that host Web containers automatically enables plug-in workload management for the application servers and the servlets they host. Routing of servlet requests occurs between the Web server plug-in and the clustered application servers using HTTP or HTTPS
This routing is based on weights associated with the cluster members. If all cluster members have identical weights, the plug-in sends equal requests to all members of the cluster, assuming no strong affinity configurations. If the weights are scaled in the range from 0 to 20, the plug-in routes requests to those cluster members with the higher weight value more often. No requests are sent to cluster members with a weight of 0 unless no other servers are available.
Weights can be changed dynamically during runtime by the administrator. A guideline formula for determining routing preference is:
% routed to Server1 = weight1 / (weight1+weight2+...+weightn)
Where there are n cluster members in the cluster.
The Web server plug-in temporarily routes around unavailable cluster members
This routing is based on weights associated with the cluster members. If all cluster members have identical weights, the plug-in sends equal requests to all members of the cluster, assuming no strong affinity configurations. If the weights are scaled in the range from 0 to 20, the plug-in routes requests to those cluster members with the higher weight value more often. No requests are sent to cluster members with a weight of 0 unless no other servers are available.
Weights can be changed dynamically during runtime by the administrator. A guideline formula for determining routing preference is:
% routed to Server1 = weight1 / (weight1+weight2+...+weightn)
Where there are n cluster members in the cluster.
The Web server plug-in temporarily routes around unavailable cluster members
What is work load management
Workload management is the concept of sharing requests across multiple instances of a resource. Workload management techniques are implemented expressly for providing scalability and availability within a system. These techniques allow the system to serve more concurrent requests. Workload management allows for better use of resources by distributing load more evenly.
Components that are overworked, and therefore, perhaps a potential bottleneck, can be routed around with workload management algorithms. Workload management techniques also provide higher resiliency by routing requests around failed components to duplicate copies of that resource.
In WebSphere Application Server, workload management is achieved by sharing requests across one or more application servers, each running a copy of the Web application. In more complex topologies, workload management is embedded in load balancing technologies that can be used in front of Web servers.
Workload management (WLM) is a WebSphere facility to provide load balancing and affinity between nodes in a WebSphere clustered environment. WLM can be an important facet of performance. WebSphere uses WLM to send requests to alternate members of the cluster if the current member is too busy to process the request in a timely fashion. WebSphere will route concurrent requests from a user to the same application server to maintain session state.
Components that are overworked, and therefore, perhaps a potential bottleneck, can be routed around with workload management algorithms. Workload management techniques also provide higher resiliency by routing requests around failed components to duplicate copies of that resource.
In WebSphere Application Server, workload management is achieved by sharing requests across one or more application servers, each running a copy of the Web application. In more complex topologies, workload management is embedded in load balancing technologies that can be used in front of Web servers.
Workload management (WLM) is a WebSphere facility to provide load balancing and affinity between nodes in a WebSphere clustered environment. WLM can be an important facet of performance. WebSphere uses WLM to send requests to alternate members of the cluster if the current member is too busy to process the request in a timely fashion. WebSphere will route concurrent requests from a user to the same application server to maintain session state.
Request routing using plug-in
The Web Server plug-in uses an XML configuration file to determine whether a request is for the Web Server of the application server. When a request reaches the Web Server, the URL is compared to those managed by the plug-in. IF a match is found, the plug-in configuration file contains the information needed to forward the request to the web container using the web container inbound chain.
For example lets say you make a request to http://localhost/sessionaffinity/SessionAffinityServlet URL, so the Web Server Plugin will check the /sessionaffinity URL to find out how it is should be handled, It will check if there is matching UriGroup element in plugin-cfg.xml
In this case it knows that the /sessionaffinity/* URL is for dynamic content, so the next part is how to route it to correct server. It will read value of Name attribute for the UriGroup which is
It knows that the cluster1 has two servers dmgrNode01_server2 and dmgrNode01_server4 and from the cluster definition it can find out the http and https port and then forward request to either of the server. The cluster definition also says that the Load balancing algorithm is Round robin
For example lets say you make a request to http://localhost/sessionaffinity/SessionAffinityServlet URL, so the Web Server Plugin will check the /sessionaffinity URL to find out how it is should be handled, It will check if there is matching UriGroup element in plugin-cfg.xml
<UriGroup Name="default_host_cluster1_URIs">
<Uri AffinityCookie="JSESSIONID" AffinityURLIdentifier="jsessionid" Name="/HelloWorldWeb/*"/>
<Uri AffinityCookie="JSESSIONID" AffinityURLIdentifier="jsessionid" Name="/NameSpaceWeb/*"/>
<Uri AffinityCookie="JSESSIONID" AffinityURLIdentifier="jsessionid" Name="/dynasession/*"/>
<Uri AffinityCookie="JSESSIONID" AffinityURLIdentifier="jsessionid" Name="/webappext/*"/>
<Uri AffinityCookie="JSESSIONID" AffinityURLIdentifier="jsessionid" Name="/dynacachereplication/*"/>
<Uri AffinityCookie="JSESSIONID" AffinityURLIdentifier="jsessionid" Name="/helloworldportlet/HelloWorldPortlet/*"/>
<Uri AffinityCookie="JSESSIONID" AffinityURLIdentifier="jsessionid" Name="/helloworldportlet/HelloWorldPortlet2/*"/>
<Uri AffinityCookie="JSESSIONID" AffinityURLIdentifier="jsessionid" Name="/helloworldportlet/*"/>
<Uri AffinityCookie="JSESSIONID" AffinityURLIdentifier="jsessionid" Name="/cachemonitor/*"/>
<Uri AffinityCookie="JSESSIONID" AffinityURLIdentifier="jsessionid" Name="/sessionaffinity/*"/>
</UriGroup>
In this case it knows that the /sessionaffinity/* URL is for dynamic content, so the next part is how to route it to correct server. It will read value of Name attribute for the UriGroup which is
default_host_cluster1_URIs, and name of the cluster is cluster1. It will use these values find out virtual host and cluster
<Route ServerCluster="cluster1" UriGroup="default_host_cluster1_URIs" VirtualHostGroup="default_host"/>
<VirtualHostGroup Name="default_host">
<VirtualHost Name="*:9080"/>
<VirtualHost Name="*:80"/>
<VirtualHost Name="*:9443"/>
<VirtualHost Name="*:5060"/>
<VirtualHost Name="*:5061"/>
<VirtualHost Name="*:443"/>
<VirtualHost Name="*:9081"/>
<VirtualHost Name="*:9082"/>
</VirtualHostGroup>
<ServerCluster CloneSeparatorChange="false" GetDWLMTable="false" IgnoreAffinityRequests="true" LoadBalance="Round Robin" Name="cluster1" PostBufferSize="64" PostSizeLimit="-1" RemoveSpecialHeaders="true" RetryInterval="60">
<Server CloneID="14dtuu8g3" ConnectTimeout="0" ExtendedHandshake="false" LoadBalanceWeight="2" MaxConnections="-1" Name="dmgrNode01_server2" ServerIOTimeout="0" WaitForContinue="false">
<Transport Hostname="dmgr.webspherenotes.com" Port="9081" Protocol="http"/>
<Transport Hostname="dmgr.webspherenotes.com" Port="9444" Protocol="https">
<Property Name="keyring" Value="C:\Cert\HTTPServer\Plugins\config\webserver2\plugin-key.kdb"/>
<Property Name="stashfile" Value="C:\Cert\HTTPServer\Plugins\config\webserver2\plugin-key.sth"/>
</Transport>
</Server>
<Server CloneID="14dtuueci" ConnectTimeout="0" ExtendedHandshake="false" LoadBalanceWeight="2" MaxConnections="-1" Name="dmgrNode01_server4" ServerIOTimeout="0" WaitForContinue="false">
<Transport Hostname="dmgr.webspherenotes.com" Port="9082" Protocol="http"/>
<Transport Hostname="dmgr.webspherenotes.com" Port="9445" Protocol="https">
<Property Name="keyring" Value="C:\Cert\HTTPServer\Plugins\config\webserver2\plugin-key.kdb"/>
<Property Name="stashfile" Value="C:\Cert\HTTPServer\Plugins\config\webserver2\plugin-key.sth"/>
</Transport>
</Server>
<PrimaryServers>
<Server Name="dmgrNode01_server2"/>
<Server Name="dmgrNode01_server4"/>
</PrimaryServers>
</ServerCluster>
It knows that the cluster1 has two servers dmgrNode01_server2 and dmgrNode01_server4 and from the cluster definition it can find out the http and https port and then forward request to either of the server. The cluster definition also says that the Load balancing algorithm is Round robin
Effect on JSESSIONID in case of Server failure
Server clusters provide a solution for failure of an application server. Sessions created by cluster members in the server cluster share a common persistent session store. Therefore, any cluster member in the server cluster has the ability to see any user’s session saved to persistent storage. If one of the cluster members fail, the user can continue to use session information from another cluster member in the server cluster. This is known as failover. Failover works regardless of whether the nodes reside on the same machine or several machines.
After a failure, WebSphere redirects the user to another cluster member, and the user’s session affinity switches to this replacement cluster member. After the initial read from the persistent store, the replacement cluster member places the user’s session object in the in-memory cache, assuming the cache has space available for additional entries.
The Web server plug-in maintains the cluster member list in order and picks the cluster member next in its list to avoid the breaking of session affinity. From then on, requests for that session go to the selected cluster member. The requests for the session go back to the failed cluster member when the failed cluster member restarts.
I tried this with my SessionAffinity.war, after establishing session with Server 2 i stopped that server and then i tried sending request to web server. The JSESSIONID was changed after 1 request and now the clone Id part was pointing to server 4

After a failure, WebSphere redirects the user to another cluster member, and the user’s session affinity switches to this replacement cluster member. After the initial read from the persistent store, the replacement cluster member places the user’s session object in the in-memory cache, assuming the cache has space available for additional entries.
The Web server plug-in maintains the cluster member list in order and picks the cluster member next in its list to avoid the breaking of session affinity. From then on, requests for that session go to the selected cluster member. The requests for the session go back to the failed cluster member when the failed cluster member restarts.
I tried this with my SessionAffinity.war, after establishing session with Server 2 i stopped that server and then i tried sending request to web server. The JSESSIONID was changed after 1 request and now the clone Id part was pointing to server 4

How to find out the WAS server handling request from JSESSIONID
Debugging problems in distributed environment is little more difficult then debugging problems in the Standalone environment, because how do you find out the server that is handling the request. The JSESSIONID cookie value contains the identifier of the server that is handling the request, take a look at Session Affinity for more details.
I wanted to try this so i created a simple SessionAffinityServlet like this
As you can see only thing that i am doing in the doGet() method is reading the value of all the cookies and writing them to output. I am also writing out name of the server handling the request in the output.
I deployed this code to server and when i tried hitting the server and i see values like this.
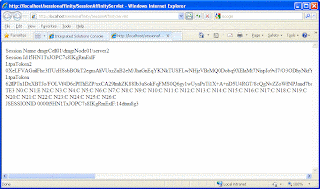
Now if i take the value of JSESSIONID the last part of the value is
As you can see the plugin-cfg.xml has a ServerCluster element that has two Server child elements, that means the cluster has two servers and plugin will forward request to either of them
You can download the sample code from here
I wanted to try this so i created a simple SessionAffinityServlet like this
public class SessionAffinityServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setContentType("text/html");
System.out.println("Inside SessionAffinity.doGet()");
HttpSession httpSession = request.getSession();
response.getWriter().println("Session Name " + ServerName.getFullName() +"
");
response.getWriter().println("Session Id " + httpSession.getId() +"
");
Cookie[] cookies = request.getCookies();
for( int i = 0 ; i < cookies.length ;i++){
response.getWriter().println(cookies[i].getName() + " " + cookies[i].getValue() +"
");
}
}
}
As you can see only thing that i am doing in the doGet() method is reading the value of all the cookies and writing them to output. I am also writing out name of the server handling the request in the output.
I deployed this code to server and when i tried hitting the server and i see values like this.

Now if i take the value of JSESSIONID the last part of the value is
14dtuu8g3. Now take this value and open the plugin-cfg.xml for web server plugin and search this value in it. You will find a Server element with value of CloneID matching the value from JSESSIONID that is the server dmgrNode01_server2 , handling the user request
<ServerCluster CloneSeparatorChange="false" GetDWLMTable="false" IgnoreAffinityRequests="true" LoadBalance="Round Robin" Name="cluster1" PostBufferSize="64" PostSizeLimit="-1" RemoveSpecialHeaders="true" RetryInterval="60">
<Server CloneID="14dtuu8g3" ConnectTimeout="0" ExtendedHandshake="false" LoadBalanceWeight="2" MaxConnections="-1" Name="dmgrNode01_server2" ServerIOTimeout="0" WaitForContinue="false">
<Transport Hostname="dmgr.webspherenotes.com" Port="9081" Protocol="http"/>
<Transport Hostname="dmgr.webspherenotes.com" Port="9444" Protocol="https">
<Property Name="keyring" Value="C:\Cert\HTTPServer\Plugins/config/webserver1/plugin-key.kdb"/>
<Property Name="stashfile" Value="C:\Cert\HTTPServer\Plugins/config/webserver1/plugin-key.sth"/>
</Transport>
</Server>
<Server CloneID="14dtuueci" ConnectTimeout="0" ExtendedHandshake="false" LoadBalanceWeight="2" MaxConnections="-1" Name="dmgrNode01_server4" ServerIOTimeout="0" WaitForContinue="false">
<Transport Hostname="dmgr.webspherenotes.com" Port="9082" Protocol="http"/>
<Transport Hostname="dmgr.webspherenotes.com" Port="9445" Protocol="https">
<Property Name="keyring" Value="C:\Cert\HTTPServer\Plugins/config/webserver1/plugin-key.kdb"/>
<Property Name="stashfile" Value="C:\Cert\HTTPServer\Plugins/config/webserver1/plugin-key.sth"/>
</Transport>
</Server>
<PrimaryServers>
<Server Name="dmgrNode01_server2"/>
<Server Name="dmgrNode01_server4"/>
</PrimaryServers>
</ServerCluster>
As you can see the plugin-cfg.xml has a ServerCluster element that has two Server child elements, that means the cluster has two servers and plugin will forward request to either of them
You can download the sample code from here
Subscribe to:
Posts (Atom)