-
First i looked at my hadoop-site.xml to find out value of
dfs.data.direlement, which points to where the data is stored. In my case its/home/user/datadirectory<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.data.dir</name> <value>/home/user/data</value> </property> </configuration> -
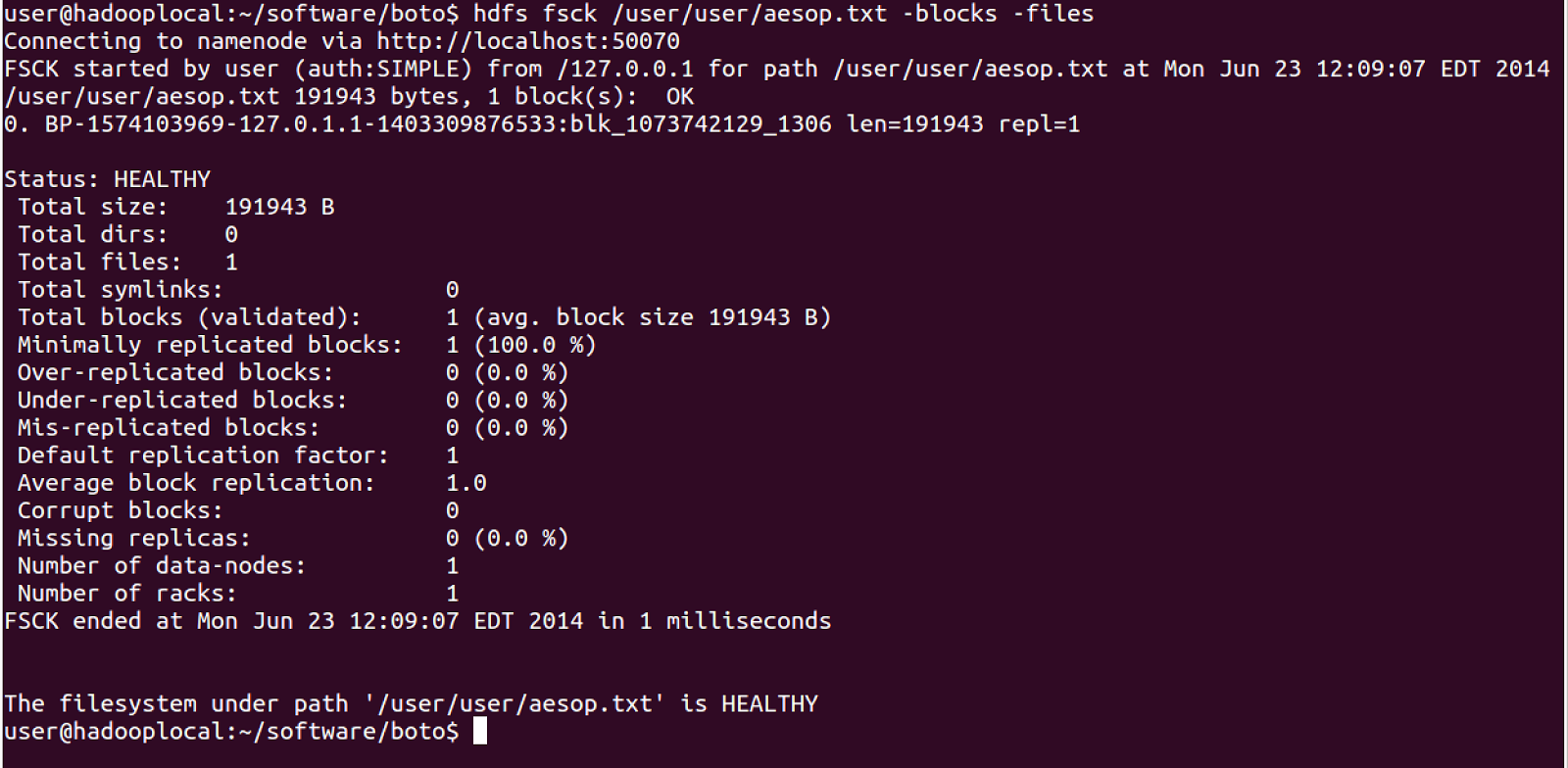
There is a file /user/user/aesop.txt stored in my HDFS and i wanted to see where the file is stored so i did execute
hdfs fsck /user/user/aesop.txt -blocks -filescommand to get list of blocks where this file is locatedIt is stored in
BP-1574103969-127.0.1.1-1403309876533:blk_1073742129_1306 -
When i looked under
/home/user/data/current directory i sawBP-1574103969-127.0.1.1-1403309876533which gives me first part of the block name, and it has bunch of subdirectories
-
The next part was to find
blk_1073742129_1306which is second part of the block name so i did search for it without _1306 the last part and i found .meta file and a normal file that contains the actual content of aesop.txt, when i opened it i could see the content of the file like this
Finding out the blocks used for storing file in HDFS
The HDFS stores files by breaking them into blocks of 64 MB in size (default block size but you can change it). It stores these blocks across one or more disks/machines, Unlike filesystem for a single disk, a file in HDFS that is smaller than single block does not occupy a fully block's worth of underlying storage.
Map tasks in Map Reduce operate on one block at a time (InputSplit takes care of assigning different map task to each of teh block).
Replication is handled at block level, what it means is HDFS will replicate the block to different machine and if one of the block is corrupted or one of the machine where the block is stored is down it can read that from different machine, in case of corrupted unreachable block HDFS will take care of replication of the block to bring the replication factor back to the normal level.
Some applications may choose to set a high replication factor for blocks in popular file to spread the read load on the cluster
I wanted to figure out how the file gets stored in HDFS(/user/user/aesop.txt file as example), so i tried these steps on my local hadoop single-node cluster.


Subscribe to:
Post Comments (Atom)
8 comments:
were you able to read the meta file? does it contain the physical disk memory address in which the file data is stored?
Hi Your Blog Is Very Nice! Attractive. Content is Nice
Stumagz is ultimate platform to release student magazine articles and engineering college news. It helps students to share their ideas in form of article.
stuMagz is an online platform that brings all the students and colleges together. Despite the fact that NBA accreditation says that every college must maintain a magazine to publish their content, there is no proper platform for students to expose themselves to the ecosystem and the lack of reach for the students to the various opportunities present in the market.There is a lack of connectivity between different colleges and universities.
The idea of stuMagz was born to bridge this gap and expand the scope for learning. It is a simple and efficient platform which provides every college and its students, a hassle free experience to publish their content and unleash their creativity.
Student Magazine Articles
Digital Campus Eco-System
Digital Stories In Hyderabad
Digital Classrooms In Hyderabad
Student Magazine Subscriptions
College Magazine Articles
College Fest Event
Top Engineering Colleges In India
For more Details Visit Us: Stumagz.com
Thank you. Well it was the nice post and very helpful information on Big data hadoop online Training Hyderabad
Wonderful post! Thanks for sharing.
Unix Training in Chennai | Unix Shell Scripting Training in Chennai | Unix Course in Chennai | Unix Certification Courses | LINUX Training in Chennai | Excel Training in Chennai | Wordpress Training in Chennai
Very useful information, if you are Looking for software courses?
DOT NET Training in Chennai
Hadoop Training in Chennai
Android Training in Chennai
Selenium Training in Chennai
JAVA Training in Chennai
German Classes in chennai
DOT NET Training in Chennai
DOT NET Course in Chennai
Thank you very much for providing important information. All your information is very valuable to me.
Village Talkies a top-quality professional corporate video production company in Bangalore and also best explainer video company in Bangalore & animation video makers in Bangalore, Chennai, India & Maryland, Baltimore, USA provides Corporate & Brand films, Promotional, Marketing videos & Training videos, Product demo videos, Employee videos, Product video explainers, eLearning videos, 2d Animation, 3d Animation, Motion Graphics, Whiteboard Explainer videos Client Testimonial Videos, Video Presentation and more for all start-ups, industries, and corporate companies. From scripting to corporate video production services, explainer & 3d, 2d animation video production , our solutions are customized to your budget, timeline, and to meet the company goals and objectives.
As a best video production company in Bangalore, we produce quality and creative videos to our clients.
This site truly has all of the information I wanted concerning this subject
and didn’t know who to ask.
UI Development Training in Bangalore
Data Science with Python Training in Bangalore
Python Training in Bangalore
AWS Training in Bangalore
Machine Learning with Python Training in Bangalore
Devops Training in Bangalore
Nice blog thank you .For your Sharing It's a pleasure to read your post.It's full of information I'm looking for and I'd like to express that "The content of your post is awesome"
Aimore Tech is the Best Software training institute in chennai with 6+ years of experience. We are offering online and classroom training.
Dotnet Training in Chennai
Core java Training in Chennai
Web design Training in Chennai
Node js Training in Chennai
Post a Comment